TOP Sprint 2026 Sign-Ups Are Open: Join the CloudRaven Labs Sprint Workspace
If you care about reliable AI over federal open data, this is the moment to join. CloudRaven Labs is actively recruiting builders, researchers, user advocates, data stewards, product advisors, and reviewers for the 2026 TOP Sprint.
TOP Sprint public story
This overview introduces the TOP Sprint, the mission behind the work, and where new collaborators can contribute. If it feels like the right fit, create your account and submit your join request to be considered for the sprint workspace.
TOP Sprint announcement visual
A campaign visual for the public collaborator invitation.

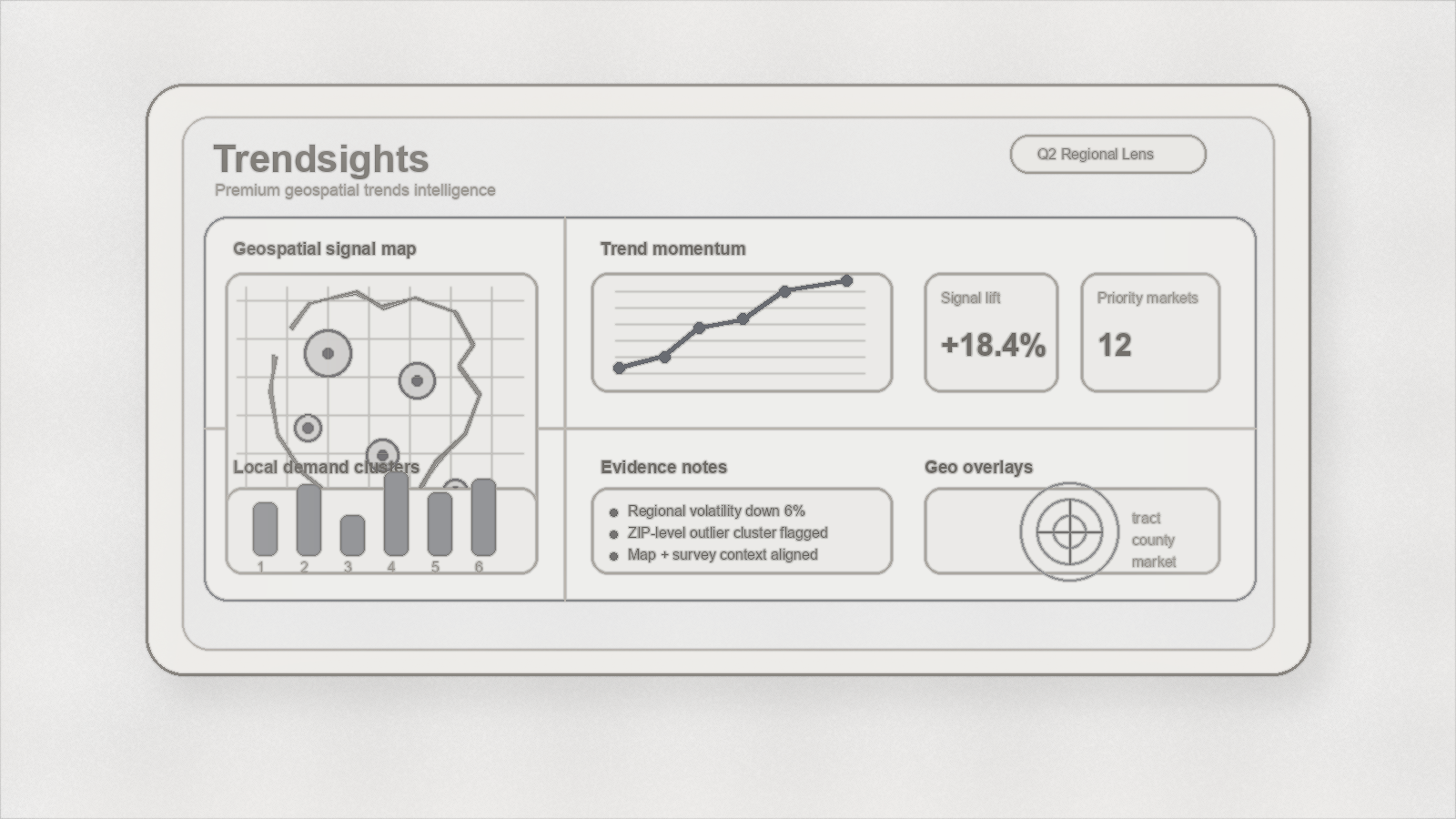
TOP Sprint dashboard sketch
A supporting dashboard concept for the geospatial public-data workflow.

On this page
Sign-ups are now open for the CloudRaven Labs sprint workspace participating in The Opportunity Project 2026 Sprint.
If you have been following the earlier TOP Sprint story and wanted a clearer answer to the practical question, this is it:
If you want to help build trustworthy AI systems over federal open data, create your account and submit your join request now.
Why this sprint matters
The official 2025 Census Open Innovation Labs sprint topic frames the challenge clearly: improve the ability of Large Language Models to serve accurate and reliable information involving federal open data, while also making that data easier for LLM systems to ingest and use well.
That challenge is exactly why CloudRaven is showing up for this work.
We are building around a simple standard: if an AI system is going to help people interpret official data, it should be able to show its sources, preserve provenance, and produce outputs that can be checked instead of merely admired.
What the program is asking teams to improve
According to the sprint topic brief, this work is not only about producing better answers. It is also about improving the underlying tooling and data usability for the next generation of AI users.
The key questions in the sprint brief are highly practical:
- Who are the people asking LLMs questions that could benefit from federal data?
- How should the data be served to support those interactions well?
- What improves content quality and accuracy in these systems?
- What essential data exists outside the current API boundary?
The brief also explicitly encourages teams to build or improve tools that integrate the U.S. Census Bureau MCP Server, including testing beta capabilities in real use cases with clear end-user benefits.
That is a strong fit for the CloudRaven lane because we are already focused on:
- authoritative citations
- reproducible outputs
- context-window efficiency
- grounded, reviewable agent workflows
Who should sign up
This is a good fit if you are the kind of person who wants to help move AI systems from plausible-sounding output toward evidence-backed results.
We are especially interested in hearing from:
- LLM and GenAI developers working on tool use, orchestration, or evaluation
- researchers who care about source quality, definitions, and evidence handling
- user advocates who can represent real workflows, panel feedback, and downstream trust expectations
- data stewards and product advisors who can pressure-test provenance, workflow fit, and adoption risk
- builders who have worked with Census, ACS, or other public-sector datasets
- designers and product thinkers who can make trustworthy systems easier to use
- sharp reviewers who can pressure-test assumptions, workflows, and user experience
The official target end users for the sprint include LLM developers and their downstream users making inquiries about federal data. That means this work matters not just for model builders, but for the real people who depend on reliable answers downstream.
What collaborators will actually do
This is not a passive mailing list.
Collaborators who join the CloudRaven sprint workspace will help shape active work across:
- agent workflows and tool integration
- data retrieval and evidence packaging
- prompt and context design
- evaluation and reliability checks
- UX for trustworthy research outputs
- user advocate panel feedback and downstream workflow review
- public story, product framing, and sprint documentation
The goal is to help build something that is credible enough to test, explain, and improve in public.
Current active team
The current working team includes:
- Rob Schaper leading the sprint lane and public program story
- Brian Schaper supporting partner systems and activation architecture
- Chandrika Kaul supporting research and geospatial open-data work
We are keeping the team intentionally focused, but we are actively looking for the right additional collaborators now.
How to register
The sign-up path is straightforward:
- Create your CloudRaven account
- Sign in to the workspace
- Choose your participant perspective and submit your TOP Sprint join request inside the private account area
That join request helps us understand where you can contribute best and how to route your onboarding, working lane, and first tasks.
If you already have an account, go directly to sign in here.
Why now
The sprint work is active, the public story is live, and this is the right moment to bring in people who want to help shape the system while key decisions are still being made.
If you want to contribute to trustworthy AI over federal open data, this is the clearest invitation:
Create your account. Submit your join request. Come build with us.
Create your account to join the sprint workspace
© 2026 CloudRaven Labs. All rights reserved.
Ready to join the TOP Sprint?
Create a CloudRaven account first. After you sign in, choose your sprint participant perspective and submit the join request inside your private workspace.