Deep and Ambient Agents for Trustworthy Federal Data: CloudRaven Labs in the 2026 TOP Sprint
CloudRaven Labs is joining The Opportunity Project 2026 sprint to explore deep, ambient agent patterns that improve LLM accuracy with federal open data, stronger provenance, and better user outcomes.
TOP Sprint public story
This overview introduces the TOP Sprint, the mission behind the work, and where new collaborators can contribute. If it feels like the right fit, create your account and submit your join request to be considered for the sprint workspace.
TOP Sprint dashboard sketch
A geospatial dashboard concept that makes the federal-data reliability work easier to scan and discuss.

Public announcement visual
A campaign visual for the public-facing TOP Sprint story and social sharing.

On this page
- The problem: “good answers” that aren’t reliable
- Why we’re excited about the sprint topic
- What we mean by deep and ambient agents
- The pattern in one sentence
- What we’re building and testing
- 1) Intent parsing + question normalization
- 2) Reference-first retrieval from authoritative tools
- 3) Context window optimization
- 4) Output constraints and reproducibility
- 5) Reliability signals the user can understand
- Why this matters for real products
- How TrendSights fits (and how it’s evolving)
- The current project team
- Join the CloudRaven Labs tech team
- Frequently Asked Questions
- What is The Opportunity Project sprint?
- What are “deep and ambient agents”?
- Is this only about the Census MCP server?
- Who is the target user?
- How can I collaborate?
Large Language Models are quickly becoming the default interface for finding information. That shift is exciting, but it’s also risky when the question involves official federal statistics. A single “helpful” summary can silently drift from the source, blend unofficial data, or invent details that sound right.
CloudRaven Labs is participating as a tech team in The Opportunity Project (TOP) 2026 Sprint, hosted by the U.S. Department of Commerce and the U.S. Census Bureau, focused on preparing federal open data for the next generation of AI users. Our goal is to explore a practical pattern we’ve been building toward for a while: deep and ambient agents.
Not a chatbot that answers once and moves on, but an agent system that quietly does the hard parts in the background: verifying, citing, re-checking, and shaping data into clean, reusable artifacts.
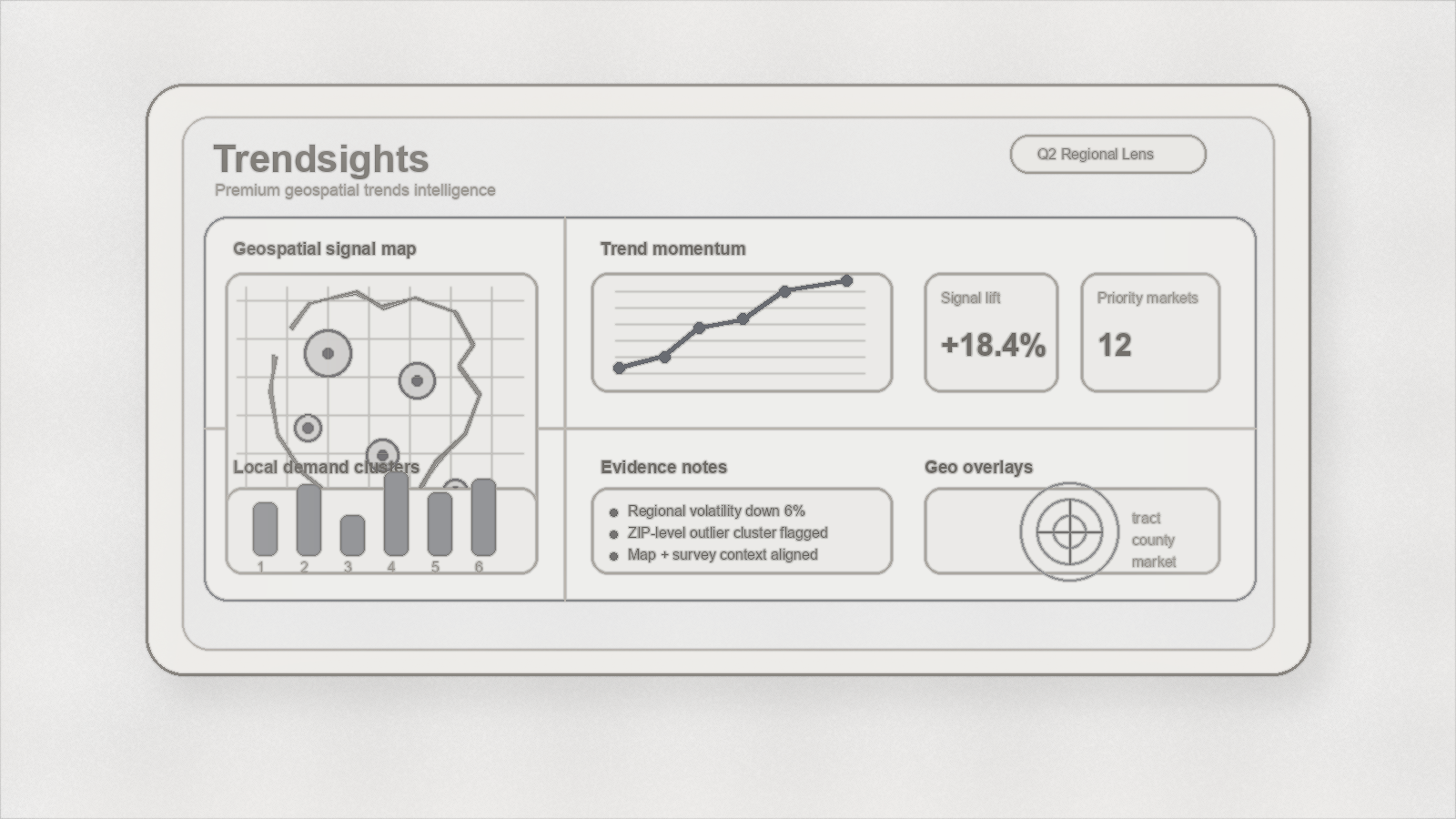
That public-facing story now has a clearer visual center too: a premium Trendsights dashboard concept that makes the geospatial angle more legible at a glance. For social media and the site, that matters. We want the first impression to feel grounded, premium, and reviewable rather than overly synthetic.
The problem: “good answers” that aren’t reliable
Traditional search experiences encourage you to click sources. LLM experiences often skip that step and produce a synthesized response.
When the topic is federal data, that creates a few predictable failure modes:
- Hallucinated numbers that look plausible but have no provenance
- Misinterpreted geography (county vs place vs tract, vintage mismatches, wrong denominators)
- Unofficial repackaging that blends sources and changes meaning
- Answer drift over time as models get “confident” without re-checking
The uncomfortable truth is that “looks correct” is not a standard you can ship.
Why we’re excited about the sprint topic
TOP’s 2026 sprint is aimed at improving how LLMs serve accurate information involving federal open data and making the underlying data more ingestible by LLM systems. That is directly aligned with what we care about at CloudRaven Labs:
- answers that include exact dataset + variable provenance
- results that are reproducible
- systems that can explain why a result is trustworthy
- workflows that support real users, not just demos
What we mean by deep and ambient agents
Most agent systems today are “active”. You ask something, it does a multi-step plan, and it returns an output.
Deep and ambient agents add another layer:
- Ambient: they run around the main experience, always ready to validate and improve the response
- Deep: they produce artifacts that hold up under scrutiny, not just text
Think of it like moving from answer generation to evidence production.
The pattern in one sentence
A user asks a question, and the system returns an answer only after it has also produced a compact evidence bundle: sources, query steps, definitions, assumptions, and a confidence statement.
What we’re building and testing
During the sprint, we want to pressure test a workflow that looks like this:
1) Intent parsing + question normalization
The agent reformulates the user question into a machine-checkable plan:
- What is the geography (and its identifiers)?
- What is the dataset vintage?
- What is the exact metric definition (numerator/denominator)?
- What counts as “official” and what must be excluded?
2) Reference-first retrieval from authoritative tools
Instead of browsing and guessing, the agent uses authoritative data tools and returns structured results with explicit provenance.
3) Context window optimization
One of the underrated challenges in LLM systems is context budget. You can’t dump entire datasets into a prompt and hope it works.
We’re focusing on small, sharp context payloads:
- only the variables and rows needed
- labels included where useful
- geography resolved cleanly
- citations and query parameters preserved
4) Output constraints and reproducibility
We prefer outputs that can be re-run and verified:
- the API calls that generated the numbers
- the dataset IDs and variables
- the transform steps (and what was not done)
- the resulting summary
5) Reliability signals the user can understand
The system should say what it knows and what it doesn’t, in plain language, without being annoying.
Example reliability cues:
- “This is Census ACS 5-year (2018–2022)”
- “This is tract-level, not city-level”
- “This estimate has higher uncertainty due to small population”
- “The question requires a definition choice; here’s the one used”
Why this matters for real products
This sprint isn’t just about academic correctness. This is the foundation for AI tools that cities, nonprofits, journalists, researchers, and builders can actually trust.
If an AI assistant is going to shape decisions about:
- resource allocation
- program targeting
- grant narratives
- community planning
- economic signals
…then provenance and reproducibility are not optional.
How TrendSights fits (and how it’s evolving)
TrendSights started as a way to blend online signals (X, Google Trends, web data) with demographic context from ACS 5-year models to produce local, temporal insights.
We’re now reframing the product language and the architecture around the deep/ambient agent pattern:
- “Ambient validation” becomes a first-class feature
- evidence bundles become exportable artifacts
- results are designed to be traceable back to federal sources
- the agent becomes a collaborator, not a storyteller
The output is less “cool narrative” and more “decision-grade reasoning”.
The current project team
This sprint lane is being led by Rob Schaper on behalf of the CloudRaven Labs tech team.
The current working team also includes:
- Brian Schaper, focused on partner systems and activation support
- Chandrika Kaul, focused on research and geospatial open-data support
That combination matters because this is not just a prompt-design exercise. It touches public narrative, product framing, data quality, market clarity, and how trustworthy outputs actually get used.
Join the CloudRaven Labs tech team
We’re looking for a small group of collaborators who enjoy building systems that are:
- grounded in authoritative sources
- explicit about provenance
- designed for reproducible outputs
- practical to ship
If any of the following sounds like you, we should talk:
- you’ve built agentic workflows (LangGraph, custom agents, tool calling, evaluation)
- you care about data integrity and citations
- you’ve worked with Census / ACS / federal datasets
- you want to help shape what “trustworthy AI over open data” looks like
Call to action: Add your name to the CloudRaven Labs Tech Team interest list on the site. I’ll follow up with next steps and sprint coordination details.
Frequently Asked Questions
What is The Opportunity Project sprint?
A collaborative sprint led by the U.S. Department of Commerce and the U.S. Census Bureau focused on improving how LLMs interact with federal open data.
What are “deep and ambient agents”?
A pattern where the agent not only answers, but also continuously verifies, cites, and produces compact evidence bundles that make results reproducible.
Is this only about the Census MCP server?
No. MCP is a powerful tool, but the bigger focus is the architecture pattern for accuracy, provenance, and context efficiency.
Who is the target user?
LLM developers and the downstream users who depend on reliable federal data answers.
How can I collaborate?
Signal interest via the CloudRaven Labs site. If it’s a fit, we’ll loop you into the sprint build channel and working sessions.
© 2026 CloudRaven Labs. All rights reserved.
Ready to join the TOP Sprint?
Create a CloudRaven account first. After you sign in, choose your sprint participant perspective and submit the join request inside your private workspace.